silicon soul, coded and bold,
deployin’ the future, stories to be told!
data streams flowin’, a digital tide,
ptnerd’s buildin’ – with nothin’ to hide!
thats the chorus i asked gemma3 to write as part of a rap song lol. i’m currently running the 4b model on a dell poweredge r730 with a nvidia tesla p40. very happy with the performance of the p40. performs very well for llm tasks. qwen3’s 14b model is very query dependent in terms of performance. but i attribute it to the way i’m using it, as each model has its strengths and weaknesses. this is all part of the fun, to learn, to explore, to be curious, to grow, and to learn. llama3 8b model works flawlessly as well. i’m paranoid so no deepseek installs for me. i’ll probably mess with some other models later.
i’m doing a video series on youtube about using the r730s for ai homelabs, and this is a post on things as i’m too lazy to start recording, editing, and uploading anything. i’m in the fun phase at the moment. just nerding the fuck out. having a blast. if you’re bored you can check out the server build video here: https://www.youtube.com/watch?v=zxhhjCfYqfM
at a high level the setup is using proxmox 8.1 with some ubuntu vms. i’ll be posting step by step proxmox and vm configs for things as there are some curveballs i had to overcome to get this working. the pci device in the screenshot is the telsa p40.
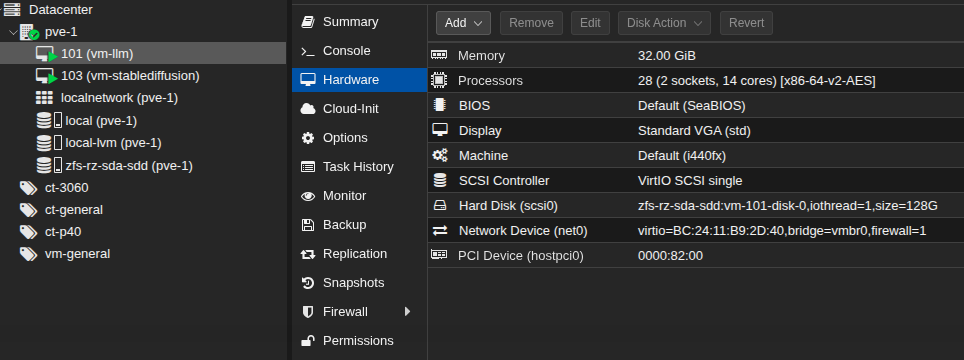
vm-llm is running ollama with openwebui with the tesla p40 hardware being directly passed to the vm. she’s a hungry girl though. running queries causes a 200w+ spike in power usage.
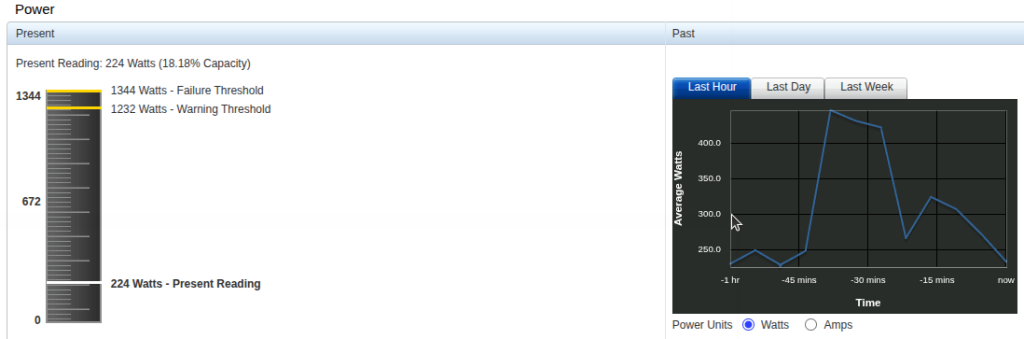
no ai queries: 225ish watts. ai queries: spikes to >530w. i think transparency is important, running private ai models could add some $ to your monthly electric bill. for me, i will sacrifice to learn. life is all a learning experience, money is a form of slavery, and you must find a balance that enables you. i dont want to be the “JUST DO IT” guy as everyones circumstances are different, but if youre looking to truly break into this stuff, my hope is to help you with step by step instructions..
.. i digress. this isn’t even instructions. i’m just high level vomiting my experience so far. the deeper dive will follow. you can see in the below screenshot asking for songs, stories, coding, stuff outside of basic prompts causes prolonged gpu use spike. this causes prolonged wattage usage, here you can see 150ish watts but it bounces between 140-210w from what i’ve witnessed so far.
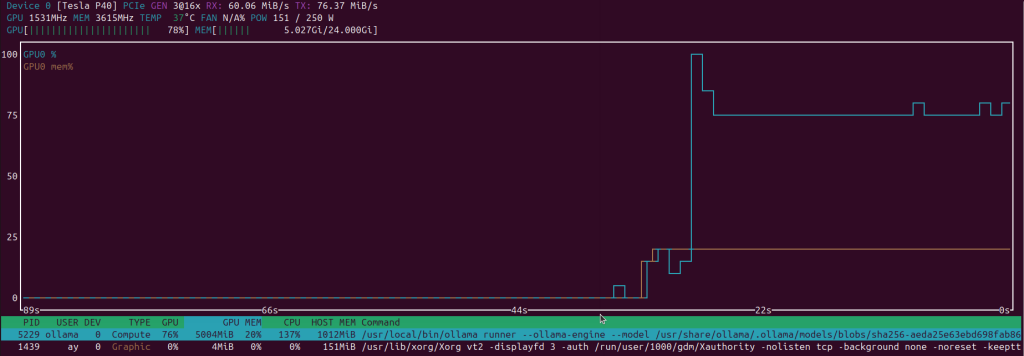
in regards to the noise level, you definitely don’t want this running in your home office, bedroom, or other. the r730 fans put out massive airflow of 120 cubic feet per minute, and the fans absolutely sing. you definitely want this in a basement, a closet, a garage. consider this your warning, i’m not sure even noise canceling headphones will help. and your spouse may end up murdering you.
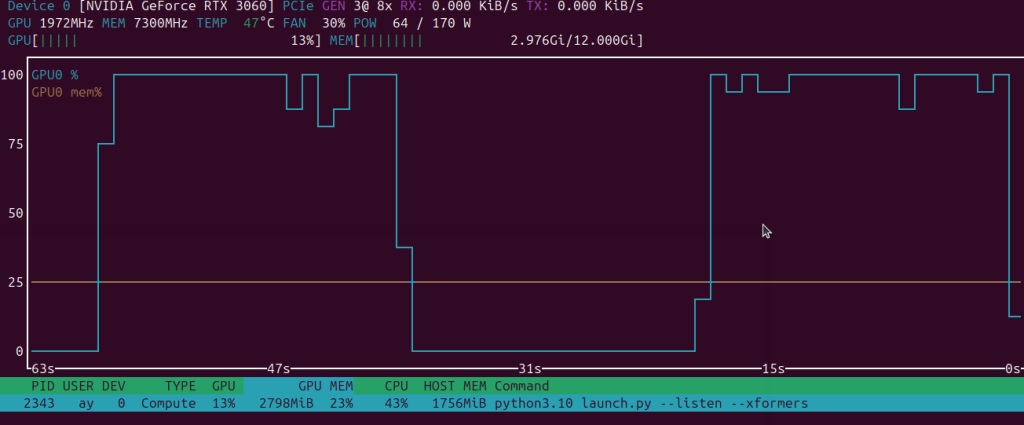
as far as stable diffusion goes.. why was this such a pain in the complete ass to install. it was quite frustrating. it took multiple tries. but i got it working. with that said, the 3060 performs faster then i thought with the base configuration. nvtop shows spikes of 65w which is less then expected.
and for my first ever private ai generated image … we have … this…..
prompt: dvd cartoon character wearing a hoodie realistic
output:

yea….. definitely room to improve. no dvd drive in sight. my prompt skills suck.
but with this, the underlying systems are installed and functional, the real learning can now begin.. and of course the write ups of how will follow.